

Remember when searching the web meant actual, precise results? The old ways of Boolean search are making a comeback, with MCP as the unlikely hero in this renaissance. Enter **mcp-server-webcrawl**, the Model Context Protocol (MCP) server that connects your web crawls and AI language models like Claude. The server turns your web crawls into a searchable datacache for your LLM to filter, analyze, and extract hard facts.
Field search includes all the regular players of HTTP, URL, status, headers, content. The full spectrum. They can be combined with advanced Boolean to create highly targeted results. In addition, you get access to fields by request, using what little LLM context you need. Just need URLs and headers? Not a problem. URLs and status codes only? Also, not an issue.
Introducing Model Context Protocol

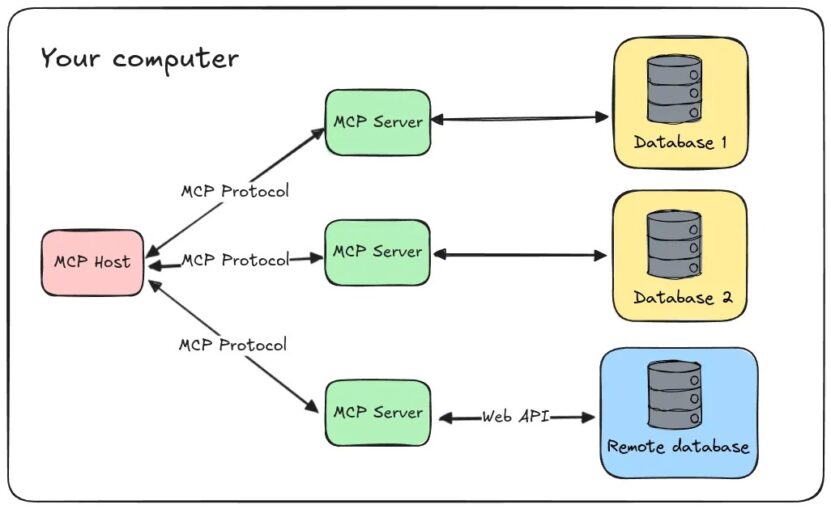
Before we dive into the implementation, let’s establish terms. Model Context Protocol (MCP) is new, and you may not have heard of it. MCP functions as an API connection between language models and external data sources—in this case, your web crawl archives. It’s the tool that lets Claude search your web crawl data without having to cram it all into a prompt or an assortment of drag and drop files.
MCP makes this possible, with mcp-server-webcrawl as the interface that brings it to life. Web content need not be copied wholesale into prompts when it can be precisely filtered using an interface tuned to search and retrieval. For additional information on this please visit https://pragmar.com/mcp-server-webcrawl/.
The Server Implementation
mcp-server-webcrawl has one role: it creates a search interface between your web crawls and the LLM. Available via pip, and configurable with a few lines of JSON.
“`
pip install mcp-server-webcrawl
“`
That’s it. One command, and you’re in business. Well, almost. You still need to configure the MCP server in Claude Desktop’s settings. Open up that config file and add something like:
“`
{
“mcpServers”: {
“webcrawl”: {
“command”: “/path/to/mcp-server-webcrawl”,
“args”: [“–crawler”, “wget”, “–datasrc”, “/path/to/archives/”]
}
}
}
“`
The Python implementation abstracts away the complexity of multiple crawler formats. Whether you’re using command line options like wget, WARC, Katana, or a GUI crawler like InterroBot or SiteOne, the backend handles the translation to a common search interface.
How It Works
The technical magic happens in several layers:
**API Layer**: mcp-server-webcrawl exposes two tools through the MCP interface: `webcrawl_sites` to list available web archives, and `webcrawl_search` to query them.
**Indexing Layer**: The server creates in-memory SQLite databases for file-based crawlers (wget, WARC, Katana, SiteOne) or connects directly to existing databases (InterroBot).
**Query Layer**: Search queries get translated into SQLite FTS5 (full-text search) operations that run against the indexed content. Boolean and field search operations are supported, and can be combined.
**Response Layer**: Results are returned through the MCP channel back to the LLM for analysis or refinement.
What’s impressive is how the Python implementation adapts to the specifics of each crawler type. It’s a virtual Swiss Army knife of crawler integrations, supporting different tools for different audiences, but all in the one comprehensive package.
Boolean Search

Let’s talk about what makes this useful. Boolean search isn’t just a bit player, it’s part and parcel of the search implementation, supporting a full grammar of search operations and field limiters that would make any developer, content administrator, or SEO pro weep with joy:
* simple keyword search: `keyword`
* exact phrase match: `”privacy policy”`
* wildcards: `boundar*` (boundary, boundaries)
* logical operators: `privacy AND policy`, `policy NOT privacy`
* field-specific searches: `url: example.com/*`, `status: >=400`, `content: h1`
* parenthetical groups: `(register OR apply) AND form`
This is top-shelf search filtering that lets the LLM zero in on exactly what it needs from your web archives.
Supported Crawlers

The Python implementation supports a handful of popular web crawlers, each with its own strengths and quirks:
**wget**: The reliable command-line workhorse. In mirror mode, it’s fast but doesn’t capture HTTP headers or status codes. In WARC mode, it’s more comprehensive but slower.
**WARC**: The archival format that preserves everything—headers, status codes, content—in a single file. Slower to create but more metadata complete.
**InterroBot**: The GUI crawler with a native SQLite database. No first-search indexing lag, preserves HTTP status codes and headers. Perfect for non-command-line folks.
**Katana**: Fast, Go-based crawler with optional JavaScript rendering.
**SiteOne**: The middle ground—GUI for operation, wget-style organization. Generates logs that preserve status codes.
The Python backend smooths over these differences, providing a unified interface regardless of which crawler you use. It’s like having different cars but the same driver’s license works for all of them.
Why it Matters
Modern, natural language search isn’t always the best option. It’s not optimized for precision, and in many cases is not tuned for your problem. This Python implementation of MCP for web crawls takes us back to Boolean basics. Search should find what you’re looking for, not what an algorithm thinks is best. In this way Boolean, fielded search can be wielded by the LLM as it filters your knowledgebase with thoroughly documented search tools.
When was the last time you saw a random sort option? There’s that too, a simplistic means of statistical sampling. Hand it over to an LLM, and you unlock the ability to run coarse testing over your web crawl, even if you have a sprawling site. (LIMIT 100 SORT ?). It’s an outlier of a feature, but one cool enough that I had to mention it.
With mcp-server-webcrawl, you’re giving your AI the power to conduct forensic analysis on your web content. Whether you’re troubleshooting technical issues, auditing content, or using your website as a knowledgebase, mcp-server-webcrawl puts Boolean precision in the hands of an AI that knows how to use it.
It takes mere minutes to set up. One pip install and a bit of configuration later, you’ve transformed your static web archives into a dynamic library of data that your AI can query with surgical precision. No more shoving entire websites into prompts. No more copy-pasting “view source.” Just connect the MCP server, ask your question, and let the Boolean search do what it was born to do: find what you’re looking for.
When it comes to search, sometimes the old ways are the best ways.